Quality Listing Photo Detector
The filter takes in a listing id and photo database to retrieve the photo URLs. A data frame of each image URL, image array, height, and width is generated from these photo URLs. A dictionary containing the listing id, image URL and reasons for passing or failing the verdict of whether the listing is of quality.
Preliminary Photo Analyses
Photo Size
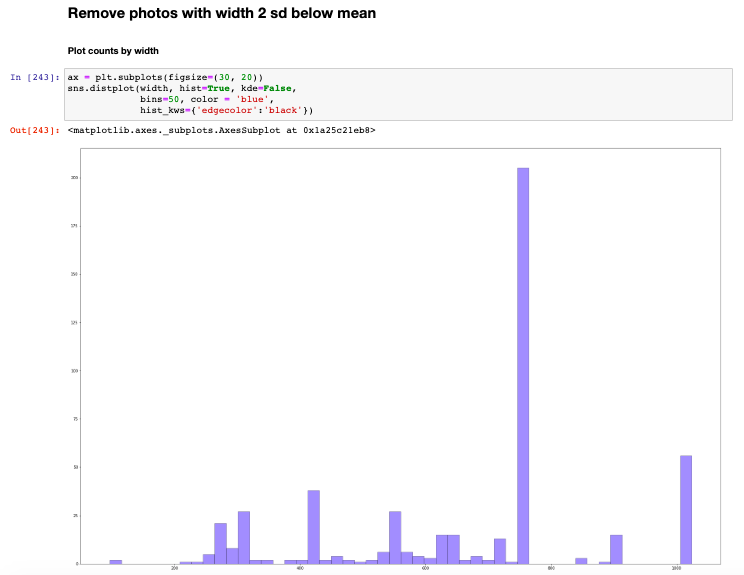
The distribution of heights and widths across the sample photos is studied first, before finding out sample means and standard deviations of heights and widths.
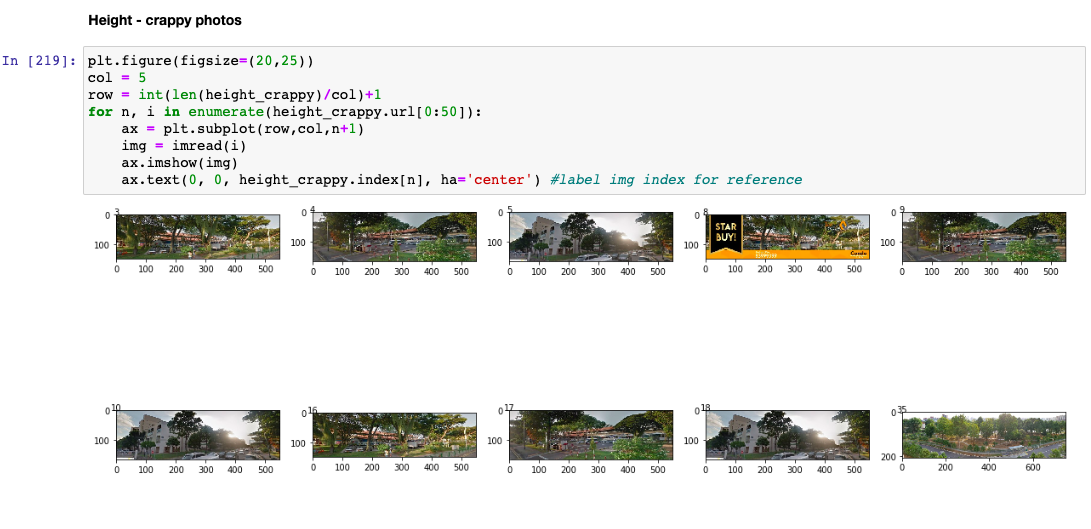
Photos with widths and heights below 2 standard deviations below the mean are filtered out as "poor quality".
Since the plot shows the distribution to be more skewed towards the left, the heights and widths are normalized before finding out their respective sample means and standard deviations and then filtering out those below 2 standard deviations.
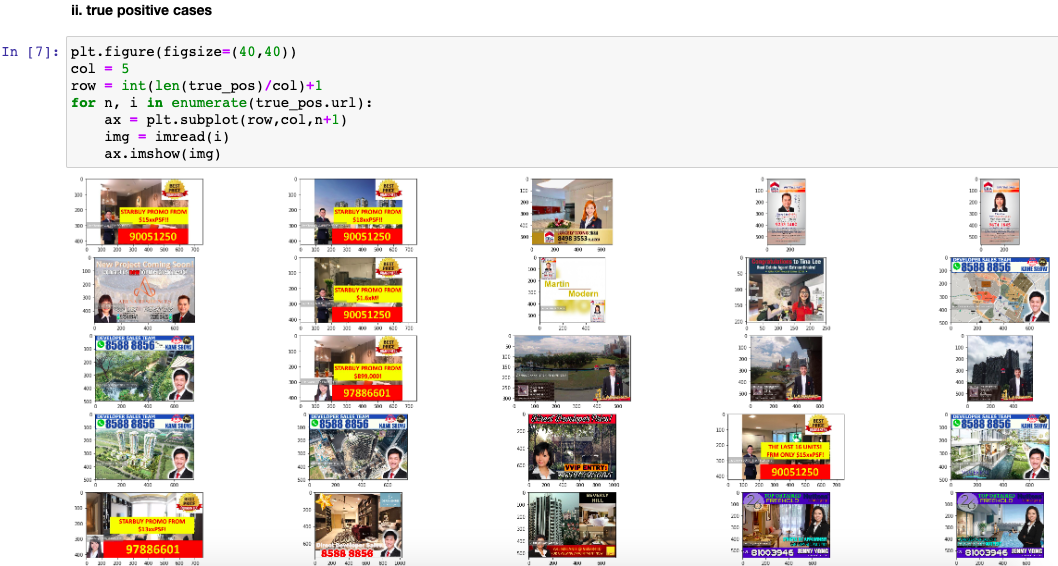
We plot the sample photos after filtering to determine the correctness of the filter.
Link to jupyter notebook: photo-size.ipynb
Face Detection & Word Detection
One attribute of a poor quality photo is one with human faces. OpenCV already has a trained model to use to detect a human face. The photo is flagged as 'crappy' if a human face is detected.
With Pytesseract, we can also filter poor quality photos with words on them.
Link to jupyter notebook: face-word-detector.ipynb
Secondary Photo Analyses
Low quality photos also includes those which are blurry or have low resolution.
Laplacian kernel scores filters out the blurry photos when set at 600. Improvements to text detection, especially white and coloured texts have yet to be explored.
Link to jupyter notebook: photo-analyses-v2.ipynb
What constitutes a poor quality photo?
- It doesn't fulfill a certain minimum height
- It doesn't fulfill a certain minimum width
- Photo has faces
- Photo has words
- Photo is blurry (via Laplacian threshold)
- Photo is oversaturated with 1 color
- Completed14 Nov 2019