Multinomial Logistic Regression & Decision Tree Scammers Analysis
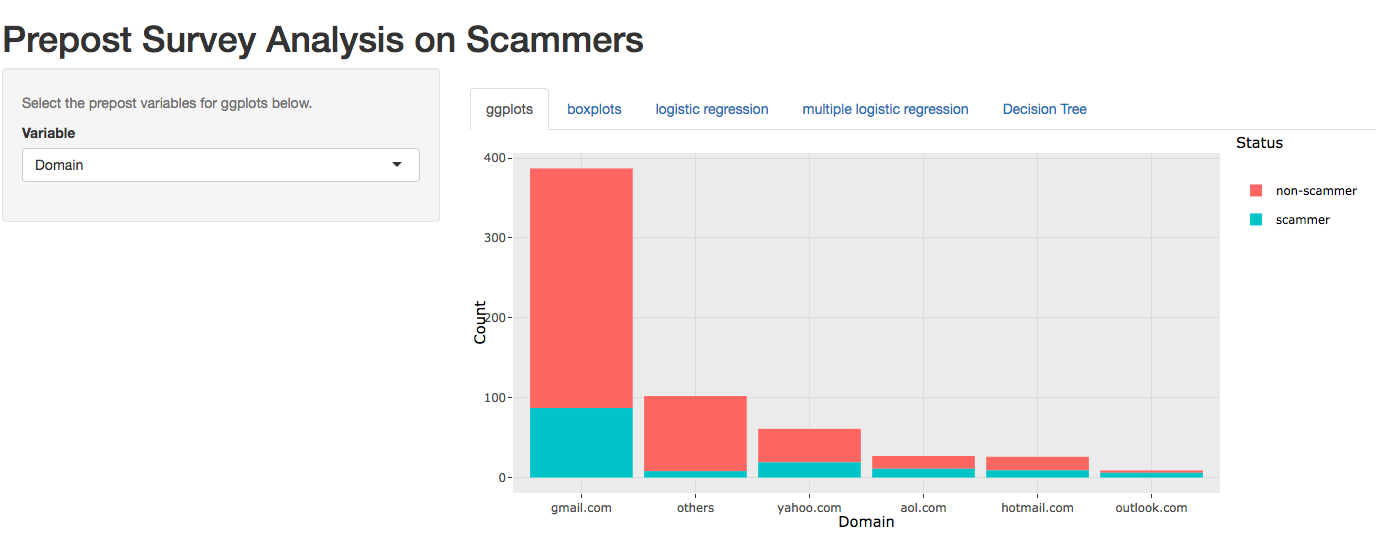
The purpose of this project is to study which aspects of a pre-listing survey is indicating whether a poster is a scammer. Firstly, multiple variables in R and Python (Json decoding blobs of data and producing GGplots in R) were preprocessed and analyzed. Unnecessary data were also removed. To view my data visualization of the project, click here.
Multinomial Logistic Regression
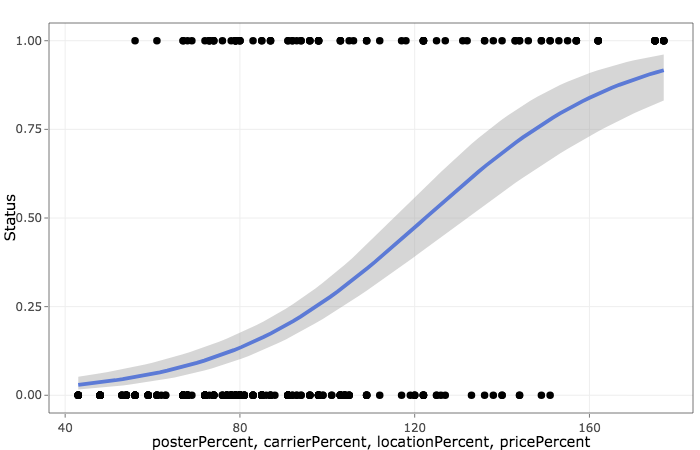
Insights from the data led me to formulate a multiple logistic regression formula with 4 most significant variables to calculate the probability of a poster being a scammer. Variables include the poster percent, carrier percent, location bucket, price bucket, which accounted for an accuracy of 89.3% and a sensitivity of 91.6%.
Decision Tree
I also developed a decision tree based on the same variables to determine if using a decision tree would be more accurate in predicting scammers as compared to using logistic regression. The accuracy of the decision tree was 88.7%, with a sensitivity of 90.0%.
- CompletedNov 2017